暗号化の対義語は復号。復号化ではないし、複合化では”もっと”ない。
状態「X」に遷移させることを「X化」という。
平文に対し暗号化を施すと暗号が出来る。これは、状態「暗号」に遷移させることであるから、暗号化という呼び方で正しい。
だが、暗号文を復号して出来るのは平文である。復号の成果物は「復号」ではない。だから、「復号化」ではないのだ。
復号はそれ自体が「暗号状態を解くこと」を指すから、ちゃんと気を付けないといけないのだ。
↓ 気になったおまけ。Google翻訳に入れてみたら(゚∀゚)アヒャ
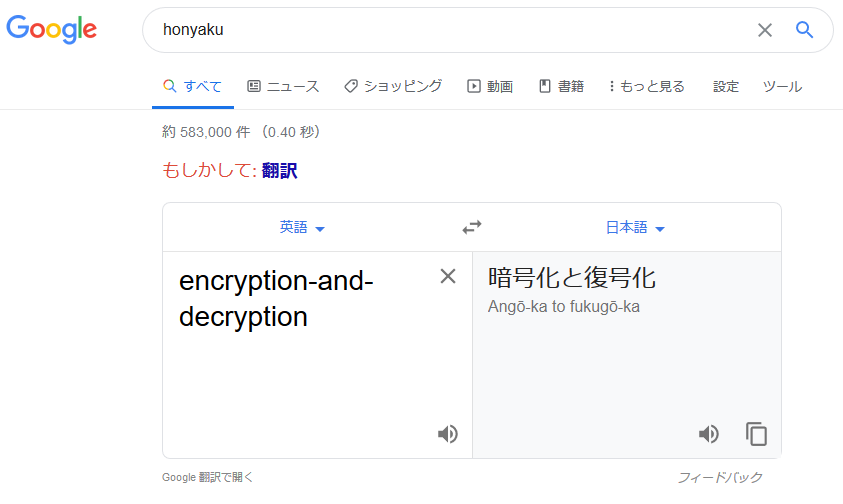
暗号化の対義語は復号。復号化ではないし、複合化では”もっと”ない。
状態「X」に遷移させることを「X化」という。
平文に対し暗号化を施すと暗号が出来る。これは、状態「暗号」に遷移させることであるから、暗号化という呼び方で正しい。
だが、暗号文を復号して出来るのは平文である。復号の成果物は「復号」ではない。だから、「復号化」ではないのだ。
復号はそれ自体が「暗号状態を解くこと」を指すから、ちゃんと気を付けないといけないのだ。
↓ 気になったおまけ。Google翻訳に入れてみたら(゚∀゚)アヒャ
このページの原文はThe Chromium ProjectsさんのSPDY: An experimental protocol for a faster webページです。Attribution 2.5 Generic (CC BY 2.5)ライセンス下のコンテンツとあったので和訳公開します。
なお、素人の意訳なので勘違いや原文と異なる表現もありえます。ご注意ください。
私たちは「WEBを高速化しよう」という活動の取り掛かりの一つとして、ページ取得にかかる時間を減らすためのいろんな代替えプロトコルを実験しています。その一つがWEB上のデータ転送時間短縮に特化したアプリケーション層のプロトコル SPDY(スピーディと読む)です。
ただプロトコルの策定だけでなく、SPDYが動作するChromeブラウザとオープンソースのWEBサーバを開発しました。研究室のテストでは、HTTPとSPDVの比較で最大64%の読み込み時間短縮を観測しました。このオープンソースコミュニティでのアイデア出し・フィードバック・コーディング・テストへの貢献がSPDYを次世代の高速WEBプロトコルに育ててくれたら幸いです。
今日ではWEBのプロトコルはHTTP+TCPです。TCPは一意性・データ順序・流れ制御・混雑回避を保証する一般的な信頼できる転送プロトコルです。HTTPは基本的な要求・応答を定義するアプリケーション層のプロトコルです。トランスポート層の改善もありだと思いましたが、まずはアプリケーション層のプロトコル、HTTPに的を絞って改善することにしました。
不幸なことにHTTPは速度重視に設計されていません。さらに今日のWEBページの転送は10年前とは大きく変化し、当時予想されなかった改善が望まれています。次に示すのはHTTPのパフォーマンスを落とす特徴です。 1コネクション当たり1リクエストのみ
HTTPは一度に一資源しか取得出来ないため、500ミリ秒間追加のリクエスト処理を行えません(一応パイプライン化という機能がありますが、それでもFIFO待ち行列を使用せねばならないという制約があります)。この問題があるので、ブラウザは複数のコネクションを張るようになりました。大抵のブラウザは2つのコネクションだった2008年から最終的には6つのコネクションまで推移しました。 クライアント側のリクエストが無いと始まらない
HTTPではクライアント側のリクエストが無いとファイル転送を行えません。サーバ側ですでにクライアントの必要なファイルがあると分かっていても、クライアント側の要求を待つ必要があるのです。 リクエスト・応答のヘッダは圧縮されない
リクエストヘッダのサイズは昔のように200バイトとは行かず2キロバイト以上にもなります。アプリケーションが多くのクッキーやユーザエージェントを使用するようになると、典型的なヘッダのうち700~800バイトは共通したものになります。MODEMやADSL接続の上り帯域はかなりしょぼいので、このヘッダ情報の削減はリクエスト時の遅延改善に直結するでしょう。 リクエストヘッダ
おまけにいくつかのヘッダは何度も何度もリクエストの度に送信されますが、ユーザエージェントやAcceptホゲホゲなんかのヘッダ情報は基本的に変わりませんし、何度も送る必要はありません。 データの圧縮転送は申告式
HTTPでは「圧縮を行ってください」と明示しないとデータは無圧縮で転送されます。コンテンツは常に圧縮されてから転送されるべきです。
HTTP高速化のためにしてきたのはSPDYの策定だけではありません。他にも、取り分けトランスポート層とセッション層レベルにおいて、高速化のためのカードがあります。 Stream Control Transmission Protocol (SCTP) トランスポート層で、ストリームの多重化や輻輳制御機能を提供する、TCPの代替となるプロトコルです。 SCTP上のHTTP SCTP上でHTTPを使おうという提案です。軽い回線ならほとんど変わりませんが、帯域が埋まるにつれてSCTP上のHTTPの方がTCP上のHTTPよりも効率がよくなるという比較実験結果があります。→ソース Structured Stream Transport (SST) 画期的な構造化されたストリームです。軽量で独立したストリームを一緒に転送できます。これはTCPやUDPに取って代わる代物です。 MUXとSMUX トランスポート層とアプリケーション層の中間層に位置するプロトコルで、ストリームの多重化を可能にします。これらはHTTP 1.1が出来る数年前に提案されたものです。
これらの提案はWEBの高速化に一役買いますが、完全ではありません。基盤となる転送プロトコルの如何によらず、HTTPに内在する圧縮・優先度などの問題は修正されるべきです。いつでもどんな人でも転送方法の変更を広めるのは大変です。が、私たちはアプリケーション層の欠点を是正すれば大きな実りがあると信じます。この方法ならインフラへの変更は極微ですし、多くのゲインが臨めますから。
SPDYプロジェクトは半端なくWEBの遅延を減らすためのアプリケーション層プロトコルの定義・実装です。
SPDYの目標は―
技術的な目標としては―
SPDYは一つのTCP接続上を複数のデータが同時に転送出来るセッション層をSSLの上に配置します。
SPDYは暗号化と回線上のデータ転送に新しいフレームフォーマットを採用しますが、HTTPのGET・ POSTメッセージの書式はそのままです。
ストリームは双方向転送対応です。サーバからでもクライアントからでも開始できます。
SPDYは普段の転送でも一歩踏み込んだ転送方法でも転送時間の短縮に成功しました。
一チャンネル上で交互にリクエストを取り扱えるので、SPDYは一つのTCP接続上でいくらでも同時転送を可能にします。必要なコネクションは少なく済む上に、1パケットの中身が密なため、その効率たるやTCPの比ではありません。.
並行してデータ転送ができるようにして一つ問題を解決すると他の問題が生じます。一チャンネルあたりの帯域幅を制限すると、クライアントはチャンネルが閉じちゃうんじゃないかという恐れから、リクエストをブロックしてしまいます。この問題を解決するため、SPDYはリクエストに優先度を設けました。クライアントはサーバへのリクエストそれぞれに優先順位を設定できます。これで混雑したネットワーク環境でどうでもいいリクエストのせいで優先度の高いリクエストが保留される心配を取り除けました。
SPDYはリクエスト・応答のHTTPヘッダを圧縮することで、転送パケットサイズを小さくします。
さらにSPDYには一歩進んだ特徴があります。server-initiated streamsです。これはクライアントからのリクエストなしにサーバ側からデータを転送する仕組みです。この設定は以下2種類いずれかの方法により実装できます。
サーバがクライアントに X-Associated-Content ヘッダを出力すれば実装できます。このヘッダは「サーバはクライアントが要求しなくてもデータ転送開始できますよ」という通知です。ユーザが最初にこのサイトを訪れた時などにこれを行えば非常に良いユーザエクスペリエンスになるでしょう。
サーバが自動的にデータを送るというより、一旦 X-Subresources ヘッダを使って「クライアントが本当にデータを求めているか」を確認してからデータを送る方法です。ただし、この方法では一旦クライアントの了解を取るまでに時間が必要になるので、低速回線では数百ミリ秒の遅れとなることもあります。が、ユーザが資源を必要としない可能性があれば良い手段ですし、そうでなくても常にクライアントから呼びかけるしかないよりはましです。
さらに詳細がしりたければ右記リンク先を参照してください SPDY draft protocol specification
こんな環境を構築しちゃいました。
研究室では試作品のSPDY対応Google ChromeブラウザとWEBサーバで、SPDYとHTTPを比較したベンチマークテストを何度も行いました。
家庭のネットワーク環境を想定した1%のパケット損失がある環境で、上位100中の25サイトのダウンロードしました。それぞれのサイトで10回ずつダウンロードを行い、平均ページ読み込み時間を算出しました。結果、SSL暗号化無しのTCPで27%~60%・SSL暗号化有りで39%~55%の速度向上が測定出来ました。
結果を下記テーブルに示します。DSL回線は上り 375 [kbps], 下り 2 [Mbps]。ケーブル回線は上り 1 [Mbps], 下り 4 [Mbps]です。
| 平均 [ms] | 速度向上 | 平均 [ms] | 速度向上 | |
|---|---|---|---|---|
| HTTP | 3111.916 | 2348.188 | ||
| SPDY 基本複数接続 TCP接続 | 2242.756 | 27.93% | 1325.46 | 43.55% |
| SPDY 基本単体接続 TCP接続 | 1695.72 | 45.51% | 933.836 | 60.23% |
| SPDY 単体接続 server push / TCP | 1671.28 | 46.29% | 950.764 | 59.51% |
| SPDY 単体接続 server hint / TCP | 1608.928 | 48.30% | 856.356 | 63.53% |
| SPDY 基本単体接続 SSL | 1899.744 | 38.95% | 1099.444 | 53.18% |
| SPDY 単体接続 クライアント先読み SSL | 1781.864 | 42.74% | 1047.308 | 55.40% |
多くの場合、SPDYは接続数によらず、全てのリクエストを一コネクションで処理出来ました。これでリクエストの並列処理が実用的レベルと分かりましたが、一部単一接続では失敗したケースがありました。これらのケースでは、SPDYはサイト毎に新しいコネクションを張る度にオーバーヘッドを受け取らねばなりませんでした。次の二種類の状況でテストをしました。
これら二つを厳密に「一サイト」と「複数サイト」のテスト結果に盛り込みました。おそらく、現実世界の結果もこれらの間に収まるんじゃないでしょうか。
ヘッダの圧縮により、リクエストで最大88%・応答で最大85%のサイズを削減出来ました。上り転送速度が375Kbpsの低速DSL回線である種のサイト、例えば多くのリクエストが必要なサイトにアクセスするサイトなんかでは、特にリクエストヘッダ圧縮が速度向上に貢献します。ヘッダ圧縮のみでも 45~1142 [ms] の無駄を省けることが分かりました。
パケット損失とRTT(Round Trip Time = 確認応答にかかる時間)がどんな影響をもたらすか知るため、二つ目のテストを実施しました。このテストではケーブル回線しか試していませんが、パケット損失とRTTのばらつきは再現しました。
SPDYの遅延改善は、パケット損失率の増加につれて顕著になりました。2%のパケット損失率の条件下では、48%の速度向上という結果が得られました。※この速度向上率はパケット損失率2%の辺りから弱弱しくなり、2.5%以上の条件下では完全に消えました。 実世界のパケット損失率は大体1~2%で、アメリカのRTTは平均50~100 [ms] です。
SPDYがパケット損失に強い理由はいくつか挙げられます。
200 [ms] のRTTで最大27%の速度向上。SPDYの遅延への強さはRTTの増加時でも観測できました。SPDYがRTTの増加に強いのは全部のリクエストを並行処理するからです。HTTPクライアントが一サイトに4つのコネクションを張って20ファイルを取得しようとしたらRTT5つ分待たねばなりませんが、SPDYでは1つ分で済みます。
| 平均読み込み時間 [ms] | 速度向上 | ||
|---|---|---|---|
| パケット損失率 | HTTP | SPDY (TCP) | |
| 0% | 1152 | 1016 | 11.81% |
| 0.5% | 1638 | 1105 | 32.54% |
| 1% | 2060 | 1200 | 41.75% |
| 1.5% | 2372 | 1394 | 41.23% |
| 2% | 2904 | 1537 | 47.7% |
| 2.5% | 3028 | 1707 | 43.63% |
| 平均読み込み時間 [ms] | 速度向上 | ||
|---|---|---|---|
| RTT [ms] | HTTP | SPDY 通常TCP | |
| 20 | 1240 | 1087 | 12.34% |
| 40 | 1571 | 1279 | 18.59% |
| 60 | 1909 | 1526 | 20.06% |
| 80 | 2268 | 1727 | 23.85% |
| 120 | 2927 | 2240 | 23.47% |
| 160 | 3650 | 2772 | 24.05% |
| 200 | 4498 | 3293 | 26.79% |
最初の実験結果でSPDYが有望なのがわかりましたが、実際の世界で使ったらどうなるかはまだわかりませんし、SPDYには改善の余地があります。特に。 帯域の使用効率はまだ悪い ダイヤルアップ帯域の効率は90%近くまで高まりましたが、高速回線の効率はまだ32%以下です。 SSLの採用がもたらす遅延・展開の問題
次の3点が問題となるので、まだSSLにはさらに改良が必要です。
パケット喪失時のテスト結果は完全じゃない 精力的にパケット喪失の調査を行っているが、現実でのWEBパケット喪失に至るモデルを十分に構築できていない。 SPDYの一コネクション再構築には複数コネクションでの通信より時間がかかる RTTがとても高い時、未だに一コネクションの利用よりも複数コネクションの利用に軍配があがる。まだ、どのタイミングでSPDYがコネクションを生成・閉塞すれば効率が良いか見極める必要がある。 サーバにはさらなる英知を詰め込める。 まだ server initiated streams やクライアントネットワーク情報を調査する必要がある。
これらの挑戦を手伝っていただけるならあなたも参加できます。:
いいえ、解決されていません。確かに一つのTCPコネクションで複数のリクエストを処理出来るようにはなりましたが、まだ一つのストリームでしかないのです。一つサイズの大きなリクエストやパケットロスが存在すると、ストリーム全体の遅延に繋がります。メジャーなブラウザはこの機能を無効にしていますので、パイプライン化を広めづらいのは明白です。
いいえ、代替ではありません。HTTPの一部分を成すことにはなりますが、概ねそのままで、アプリケーション層の最上位では全く同じです。SPDYはHTTPのメソッド・ヘッダ・その他の成分を用います。ただ、SPDYはコネクション管理やデータ転送形式など、プロトコルの一部を改良するだけなのです。
速度(SPEED)を言い得た命名を望んでました。圧縮(無駄を省略すること)が転送速度を改善するというところと、読みがスピーディだというところから決めました。
トランスポート層プロトコルの切り替えが高速化に有意かどうか判別するにはもっと調査が必要です。トランスポート層のプロトコル切り替えにはただならぬ複雑な努力が必要ですが、TCPとHTTPをアプリケーション層で変更できれば、今より楽になると思います。
いいえ、心配御無用です。SPDYはTCPと互換性があるので、TCPの輻輳制御アルゴリズムの恩恵に肖れます。さらにいえば、HTTPはすでにインターネットの輻輳制御方法を捻じ曲げちゃっています。例えば、最近のブラウザは一つのWEBサーバに対して6つのコネクションを生成してますし、WEBサーバ側も最初のデータ格納サイズを4パケット分に増加させてます。TCPコネクションそれぞれが独立だから、最初は 6 * 4 = 24 パケットを転送することになるわけです。これでは初動が遅くなってしまうので、SPDYでは対照的に一つのコネクションのみで実装することにしたわけです。
SCTPは面白いトランスポート層の代替プロトコルです。一コネクションで複数のストリームを転送できるようになる訳ですが、悲しいことに使いたければ家のルータを変更するなど転送スタックへの変更が必要になります。また、SCTPだけじゃ銀の弾丸にはなりません。効率よく使うには、サーバ・クライアント間でアプリケーション層の変更もまた必要になるのです。
BEEPは福袋のような特徴を持つ面白いプロトコルで、ページ読み込み高速化に的を絞って設計されたわけじゃありません。バイナリではなくてテキストをベースにしたプロトコルでいろんな拡張ができますが、ちょこっとセキュリティに問題があり、正確に転送するのは難しいです。
MySQL5.5を用いた通常・準同期レプリケーション構築の解説です。レプリケーションとは何か、通常・準同期レプリケーションの対比、構築方法、必要な保守作業など。対象読者は多少MySQLサーバの設定を行ったことのある方を想定しています。
レプリケーションを構成する要素・どんな動作をするか・レプリケーションの種類。レプリケーション構築の前に知っておくべきことを解説します。
MySQLのレプリケーションはマスターサーバのデータを一つ以上のスレーブサーバに複製することでデータを冗長化する機能です。
レプリケーションを用いれば複数個所にデータベースの複製を設置できるので、荷分散と共に可用性・信頼性を向上させられます。設定は容易で、どのサーバからもSELECT文でデータを参照できます。しかし、更新クエリはマスターサーバにしか行えません。つまり、レプリケーションで書き込みのスケールアウトは出来ません。更新クエリの負荷を分散させる必要が無い場合にはレプリケーションをお勧めします。更新クエリの負荷分散が必要な場合は、クラスタリング設定を行うか、別のソフトウェアを試してください。
通常レプリケーション特筆すべき点は、マスターサーバはログを出力するだけで自己完結していることです。スレーブサーバの片思い的な動作方式です。
マスターサーバの役割は単純で、更新クエリ実行時にバイナリログを出力するだけです。
スレーブサーバは下記の通り多少がんばります。
スレーブサーバはバイナリログ実行後すぐにログアウトするわけではなく、実際は2~3の動作を繰り返します。
実際に更新クエリをコミットした時の振る舞いを見ましょう。
手順「2.」の転送が完了する前にマスターがクラッシュした場合、齟齬が生じ「コミットしたのにデータが巻き戻されてる」という事態に陥る可能性があります。
準同期レプリケーションのシステム構成要素は通常のレプリケーションと共通。PostgreSQLで言う同期レプリケーションと同じ仕組みです。準同期レプリケーションではマスターはスレーブの面倒を見ます。毎朝登校時間に起こしに来てくれる幼馴染型の動作をします。
マスターサーバの役割は通常レプリケーションよりも増えます。
スレーブサーバは気楽です。
スレーブサーバはバイナリログ実行後すぐにログアウトするわけではなく、実際は2の動作を繰り返します。
一定時間(設定で変更可能)待機してスレーブからの応答が無い場合、マスターはスレーブを無視してバイナリログをコミットします。
実際に準同期レプリケーションを構築したMySQLサーバで更新クエリをコミットした時の振る舞いを見ましょう。
この動作手順では、最初にSQLバイナリログを送信しているため、MASTERとSLAVE間で齟齬が生じる可能性は非常に低いです。
通常レプリケーションの動作と準同期レプリケーションの動作で見てきたように、構成する要素は同じで動作の違いは小さいです。が、それぞれ癖がありますので、どちらを選択するかは吟味しておくべきです。
両者の対比を紹介しますが、データの完全性を求めるなら準同期レプリケーション。数分の更新遅延を気にしないなら通常レプリケーションが私の結論です。
準同期レプリケーションはクエリ実行時にバイナリログをスレーブに送って応答を待つため、通常のレプリケーションよりコミットまでの応答時間が長くなります。
通常レプリケーションで、マスターが更新したバイナリログを取得する前にマスターが落ちると、「コミットしたのに巻き戻ってる…」という自体に陥る可能性があります。また、マスターがコミットしてからスレーブがコミットするまでの間にスレーブのデータを参照すると、古いデータを読み込むことになります。つまり、通常レプリケーションは完全性に難があるわけです。金銭を取り扱うようなシステムでは通常のレプリケーションを控えねばなりません。
保守は通常レプリケーションの方が楽です。マスターはスレーブと完全に独立して動作していますし、スレーブを落としてもマスターの動作が遅くなることはありません(準同期では一定時間スレーブの応答を待機する)。そして、多少設定が楽です。
複数のレプリケーションを構築する場合も手順は同じなので、『一台のマスター・一台のスレーブ』を構築します。
手順
下記の構成でレプリケーション構成を行います。分かる変数を各自の環境に合わせたら次に進みましょう。
SSHなどを用いて実際にサーバ機を操作します。
レプリケーションを行うには、マスター側のMySQLサーバの使用するポートが外部に公開されている必要があります。MASTERでファイアーウォールを利用している場合、TCP 3306 番ポートを開放して下さい。また、アウトバウンドのサーバとレプリケーションを行う場合は、ルータのネットワークアドレス変換を設定してください。
まず、レプリケーション権限のみを持ったレプリケーション専用のユーザーを作成します。MASTERのMySQLコンソールで以下のSQLを実行します。
GRANT REPLICATION SLAVE ON *.* TO replication_user@'slave.example.com' IDENTIFIED BY 'password';
ユーザ作成に成功したら、設定を反映してください。
FLUSH PRIVILEGES;
レプリケーション構築の勘所で、すべきことは下記2点です。
「1.」では設定読み込みのためにMySQLサーバを再起動する必要がありますし、「2.」ではデータコピー中にユーザがデータベースに書き込めなくする必要があります(バックアップ中にデータを更新されては困る)。途中で手を止めるとサーバ停止時間が伸びてしまうので、ひと通り手順をさらってから作業に進んでください。 マスター用の設定を行う
「マスター用の設定」とは、下記三点のことを指します。すでに設定済みの場合はスキップしてOKです。
これらの変更はvi /etc/my.cnf で [mysqld] 中に下記を追加して行います。
編集したら /etc/rc.d/mysqld restart でマスターを再起動し、設定を反映してください。 スレーブ側にマスターのデータを転送するため現在状況を複製する
下記役割を持つ、A,・B 2つのターミナルを用意します。
~ここからノンストップ作業~
ターミナルAで下記SQLを実行し、 MySQLサーバの書き込みを禁止します。※ログアウトするとロックが解けてしまうため、コピーが完了までAはMySQLサーバからログアウトしてはいけません。
FLUSH TABLES WITH READ LOCK;
下記SQLを実行し、現在のログ位置を取得します。FileとPositionの値をメモしておいてください。→上のフォームにメモってくる
SHOW MASTER STATUS;
mysql> SHOW MASTER STATUS;
| File | Position | Binlog_… |
|---|---|---|
| mysqld-bin.000001 | 805 |
1 row in set (0.00 sec)
スレーブ側にデータを転送する前に圧縮します(データサイズや回線速度によっては圧縮せずに cp を使った方が速く終わる場合もあります。要はマスターのDBデータをスレーブにコピー出来れば良いので、適宜方法を選択してください)。
tar zcvf master-mysql-data.tar.gz *ターミナルAで下記クエリを実行してロックを解除してください。
UNLOCK TABLES;
~ここまでノンストップ作業~
前項で作成したマスターデータベースの複製をスレーブに転送します。転送方法はSFTPでもFTPSでもSCPでもUSBメモリでもフロッピーディスクでも構いません。
下の例ではマスター側のコンソールでSFTPを使って転送します。
スレーブとして動作するように設定ファイルを編集します。
vi /etc/my.cnf で [mysqld] 中に下記を追加してください。
※旧ヴァージョンのMySQLサーバでレプリケーションを行っていた方へ…MySQLのヴァージョン5.5未満のレプリケーションで使用していた master_host, master_port, master_user, master_password の設定項目は、my.confに記述できなくなりました。これら変数を my.cnf に記述してMySQLサーバーを起動しようとすると、 /var/log/mysqld.log には [ERROR] /usr/libexec/mysqld: unknown variable ‘master_host=master.example.com’ とエラーメッセージが出力され、起動ができません。これらの変数はSLAVEで CHANGE MASTER TO ... クエリを実行した時に自動的に /var/lib/mysql/master.info に書き込まれるようになりました。
編集したら /etc/rc.d/mysqld restart でSLAVEを再起動し、設定を反映してください。
スレーブサーバに「どのMySQLサーバをマスターとするのか」の情報を与える必要があります。スレーブのMySQLコンソールで下記SQLを実行してください。
CHANGE MASTER TO master_host='master.example.com', master_port=3306, master_user='20', master_password='password', master_log_file='mysqld-bin.000001', master_log_pos=805;
実行後 /var/lib/mysql/master.info が生成されるのが確認できます。
スレーブのMySQLコンソールで下記SQLを実行してください。
START SLAVE;
SLAVE側のMySQLコンソールで下記クエリを実行し、レプリケーションが構築できているか確認してください。エラー無くマスターと同じ位置までログが進んでいれば正常です。
SHOW SLAVE STAUS;
スレーブサーバのPC再起動です。PCを再起動してもスレーブ状態は維持されます。レプリケーションの再設定(START SLAVE)が不要なのが分かりました。
マスターでの更新クエリ実行です。マスターにテーブルを作って、SLAVE側で反映されるかを確認してください。
CREATE DATABASE hoge;
SLAVE側でも同じ更新が行われるはずです。
※レプリケーションが壊れる可能性があるので本番環境でこのテストを行わないでください。
スレーブ側で更新クエリを実行するとどうなるか。スレーブ側でも更新クエリは実行できてしまいます。マスターとデータの齟齬が生まれてしまうので、SLAVE側での更新は行わないようにしてください。スレーブ側でデータベースを更新出来なくするのもひとつの手ですが一長一短です。スレーブ側で更新できるなら、マスターが不慮に停止しても迅速にサービス復旧できるからです。
準同期レプリケーション構築時、スレーブがダウンしている場合の動作です。スレーブのMySQLサーバーをストップしてからマスターで更新クエリを実行すると、 rpl_semi_sync_master_timeout で指定した時間 [ms] 待機してから更新クエリが実行されます。このクエリ実行後にスレーブのMySQLサーバーを立ち上げると同じ更新が行われました。スレーブがダウンしても expire_logs_days で示した日数以内に再起動出来れば問題ないようです。
レプリケーション構築後にどんなメンテナンスが必要かと言っても場合によりけりなのですが。個人的にチェックすべきと思った点を抑えます。
スレーブサーバが死んだ時はほぼ問題無しです。準同期レプリケーションであれば更新クエリ実行時に rpl_semi_sync_master_timeout で指定した時間待機するので多少パフォーマンスが低下しますが、これまでの手順どおりに再度レプリケーションを組み直せば良いだけです。
問題はマスターサーバが死んだ場合です。フェイルオーバーが必要になります。マスターサーバが息をしていない場合はスレーブサーバで下記クエリを実行してください。
RESET MASTER;
これでスレーブはマスターに昇格し、元マスタのバイナリログを読みに行かなくなります。なお、既存のバイナリログ関係ファイルはすべてリセットされます。
データベースの更新頻度が低ければ2週間のバイナリログ自動削除で大丈夫ですが、更新頻度が高くなるとものすごい勢いでバイナリログが書き込まれることになります。「ハードディスクの中がログファイルでパンパンだぜ」という事態に陥る可能性があるわけです。時折ハードディスクの残量とバイナリログの増加速度を見てバイナリログの保持期間を調整してください。
レプリケーションを組むだけで安心してはいけません。RAIDを組んでもバックアップは別途必要と言われるように、レプリケーションを組んでもDBのバックアップは別途取得するようにしてください。
貴方の中の全どぢっ娘がうっかりデータ全削除をしてしまう可能性はゼロではないからです。
MySQL5.5で準同期レプリケーションをしようとした時に、頭から尻尾まで解説したサイトが見つかりませんでした。大抵、通常のレプリケーションを組んであるのが前提だったり、細部がはしょってあったり。それで、MySQL5.5を用いた準同期レプリケーション設定の解説をしようと思いました。
しかしながら、なかなかうまくいかないもので。作ってから「僕の解説中途半端だお…」と気づきました。気付いたもののなかなか更新出来ず、半端な解説を掲載したまま一年近くが経過してしまいました。
数日ああでもないこうでもないと考えて作成したMySQL5.5+準同期レプリケーション構築の解説ドキュメント。多少なり役立てたのであれば幸いです。
とみんのブログ – 今更ながらMySQLのレプリケーション その1 準同期レプリケーションについての解説しています。
現場指向のレプリケーション詳説 運用しながらのレプリケーションの構築方法を解説しています。
半袖野郎 blog.hansode.org – 2009年05月08日 master.infoの構造・作り方を解説しています。
OpenGroove – レプリケーション時のRESET MASTERとRESET SLAVE レプリケーション時のRESET MASTER・RESET SLAVEコマンドの動作を解説しています。